We introduce Macaron-V1-Preview, a 749B (744B base + 5 × 1B LoRA) Agent Model post-trained from GLM5.1 with MinT. Macaron-V1-Preview leverages a novel Mixture-of-LoRA (MoL) architecture to provide a scalable, resource-efficient foundation for advanced agentic use cases in general life scenarios.
By orthogonalizing the parameter space through the MoL architecture, Macaron-V1-Preview reduces the optimization interference that often appears when one model is trained for diverse agentic capabilities. Each capability is optimized in its own adapter space, allowing synergistic capabilities to improve together while isolating conflicting objectives to prevent mutual degradation. This gives the model nuanced emotional intelligence and multi-turn coherence in Chat, contextually accurate API generation in Tool Use across dynamic domains such as travel, daily essentials, and entertainment, and strict syntax adherence in Coding for streaming and interactive frontend generation.
This consolidation also reshapes how the model is trained and served. Upstream, freezing the 744B base concentrates compute on the 1B adapters, and pipelines such as Rollout Routing Replay (R3) keep RL stable on each one for targeted, low-overhead adapter updates. Downstream, this enhances the application experience by delivering lower cognitive load, higher information density, and a frictionless progression from conversation to action.
1. Living with the User
A great personal agent has to live where the user lives. Daily life is full of small, contingent decisions: what to eat tonight, where to find a quiet table, how to reroute when traffic shifts, when to fit the dentist around a kid's pickup. None of these are individually hard. They are hard in combination, in motion, against a user whose intent and patience are also moving. To navigate this constant, dynamic friction, we think a good personal agent has to balance three essential qualities: it must be capable of executing real-world tasks and complex reasoning, coherent by maintaining memory and context across long conversations, and expressive in instantly delivering information through the most effective interface—whether that's a simple sentence, a visual card, or an interactive tool.
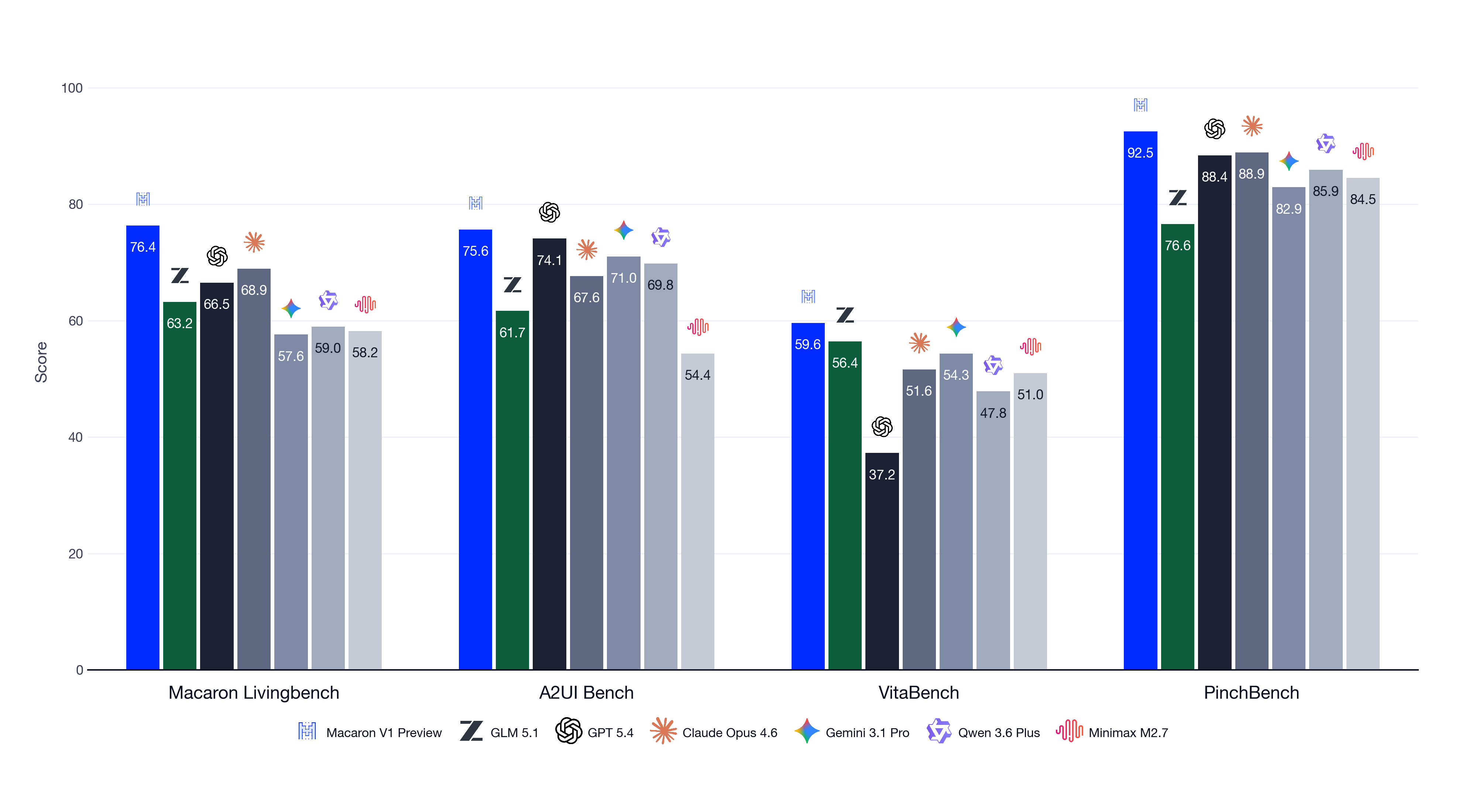
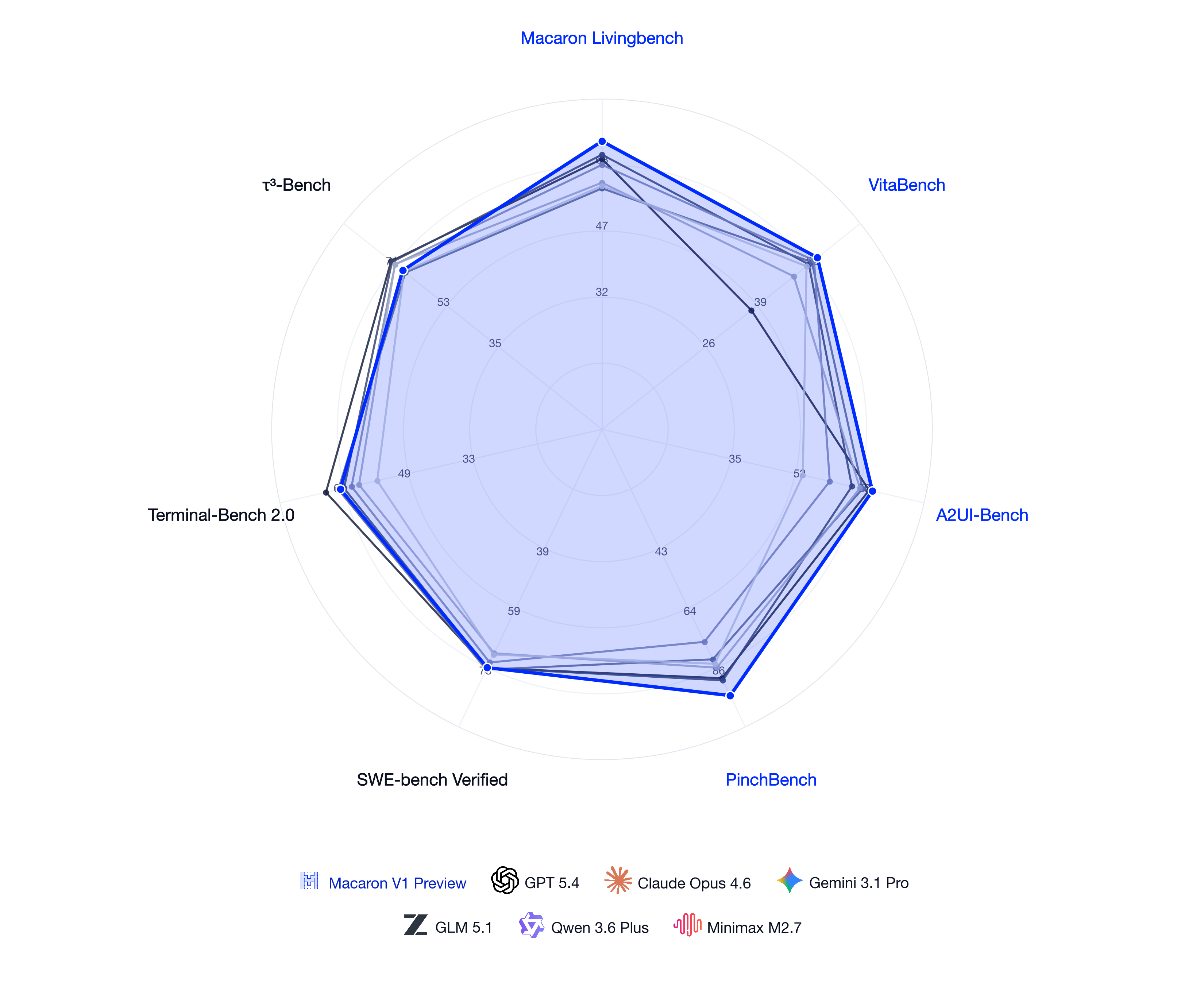
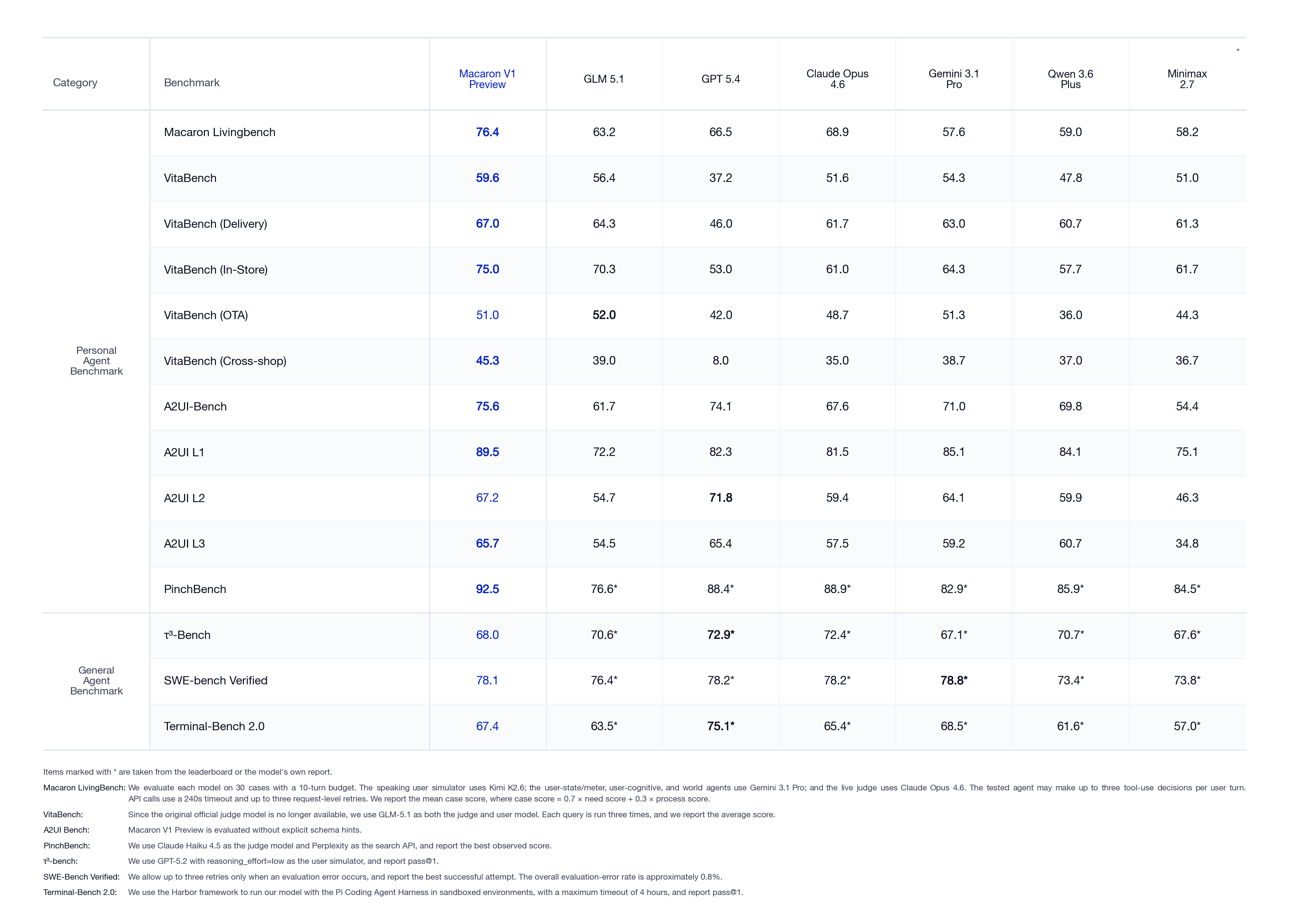
We chose evaluations that match this picture. Macaron LivingBench is our flagship benchmark for real, dynamic personal-life scenarios distilled from the Macaron App. VitaBench covers concrete daily-life surfaces like ordering food and navigating around the city. PinchBench evaluates OpenClaw-style multi-step personal-assistant workflows. We also keep an eye on SWE-Bench Verified and Terminal-Bench 2 on the coding side, and on τ³-bench for general capability. On this last group our goal is explicitly not a top score, only that the underlying capability holds steady. The capability we push hardest on, alongside personal-life agentic behavior, is Generative UI (measured on A2UI-Bench), because how the model talks back matters as much as what it figures out.
1.1 The Person on the Other End of the Conversation
A great agent starts with great chat. And great chat is irreducibly subjective: it is shaped by a user’s preferences, projection style, interaction habits, and most of all by how they read and value language itself. Two users meeting the same emotional moment can call for very different responses, and serving both well calls for something richer than a single, flat persona.
So we trained against four coupled dimensions of conversation at once: personality, the model holding its own stances and sharing them; character, behavior that stays consistent across pressure, conflict, and many turns; depth of thought, engaging hard questions with a real angle while staying open to other ones; and chat experience, the rhythm of a real conversation, knowing when to stay quiet, when to land one good sentence instead of three bullets.
1.2 LivingBench: A Benchmark That Lives
Macaron LivingBench is our in-house agent benchmark for real-life scenarios and dynamic tasks. Real users share their needs in pieces, and the world keeps moving while the agent works. The restaurant runs out of seats. The route stops making sense once the weather and traffic shift. The user remembers a budget cap, a privacy concern, a family obligation, three turns in. The data sources the agent reaches for can be incomplete, stale, or contradictory across apps.
To capture this, LivingBench is a simulated sandbox with three coupled forms of dynamism: dynamic noise, a dynamic life environment, and a dynamic user. The task is allowed to drift mid-trajectory the way real life does. We watch whether the model can keep understanding the user, verify information, replan, handle surprises, respect privacy, and finish the task while the user still has patience for it.
The benchmark has three layers. At the data layer, each scenario starts from one real user need; the character and her environment are generated together, so contradictions in mood, history, and constraints are baked in by design rather than sprinkled in as noise. The sandbox layer runs a high-fidelity user simulator with a modular cognitive architecture (mood, recent events, cognitive load) on top of noisy tool returns; it shares information progressively, based on whether the agent is earning her trust. The evaluation layer judges success by the end-state of the world the user actually lives in, with per-case rubrics and aggregated process-level scores across UX dimensions like latency, intrusiveness, and recovery from error.
LivingBench is not a frozen test set. It is tightly coupled with the product, and new scenarios are continuously distilled from real user needs and human-AI friction in production. The benchmark grows alongside both the product and the frontier of model capability, so it stays as alive as the users it represents.
1.3 Generative UI: A Model That Speaks in Surfaces
Generative UI is one of the capabilities we care about most, and we believe it is a core capability for any personal model. It is how the model interacts with the user. Without it, the model can answer well but cannot show, choose, adjust, or hand a control back, and for a personal agent the quality of that interaction is on the same level as the quality of its reasoning.
We trained the model directly against Google’s A2UI protocol, and built A2UI-Bench to score it. A2UI-Bench evaluates Generative UI along three layers: protocol correctness (are the emitted A2UI actions well-formed and faithful to the protocol’s semantics), task construction correctness (do the actions add up to a UI that actually answers the user’s request), and real user-experience lift (does the resulting interaction make the task genuinely easier than a text-only response). On top of that, a visual-side evaluation renders each payload in a real client and looks for what a language judge cannot see, like content overflow, broken layouts, controls hidden off-screen, or spacing that quietly destroys the surface.
Capability is only half of Generative UI. The other half is how fast the surface arrives. A real-time UI that takes longer than five seconds to compose is something the user has already moved past, so latency is a hard product requirement. Through our collaboration with the TileRT team, we optimized A2UI inference speed to 3 ms TPOT in dynamic interactive UI‑generation scenarios. Meanwhile, we extended the A2UI protocol itself in places where it was not flexible or general enough for the surfaces a personal agent really needs. Together, this is what lets Macaron put a useful surface in front of the user inside the window where the user is still paying attention.
2. Technical Details
Macaron-V1-Preview is a model and harness co-design. The model is post-trained from GLM5.1 with a Mixture-of-LoRA architecture, and the harness is the runtime that makes that architecture serveable, trainable, and stable.
2.1 Mixture-of-LoRA
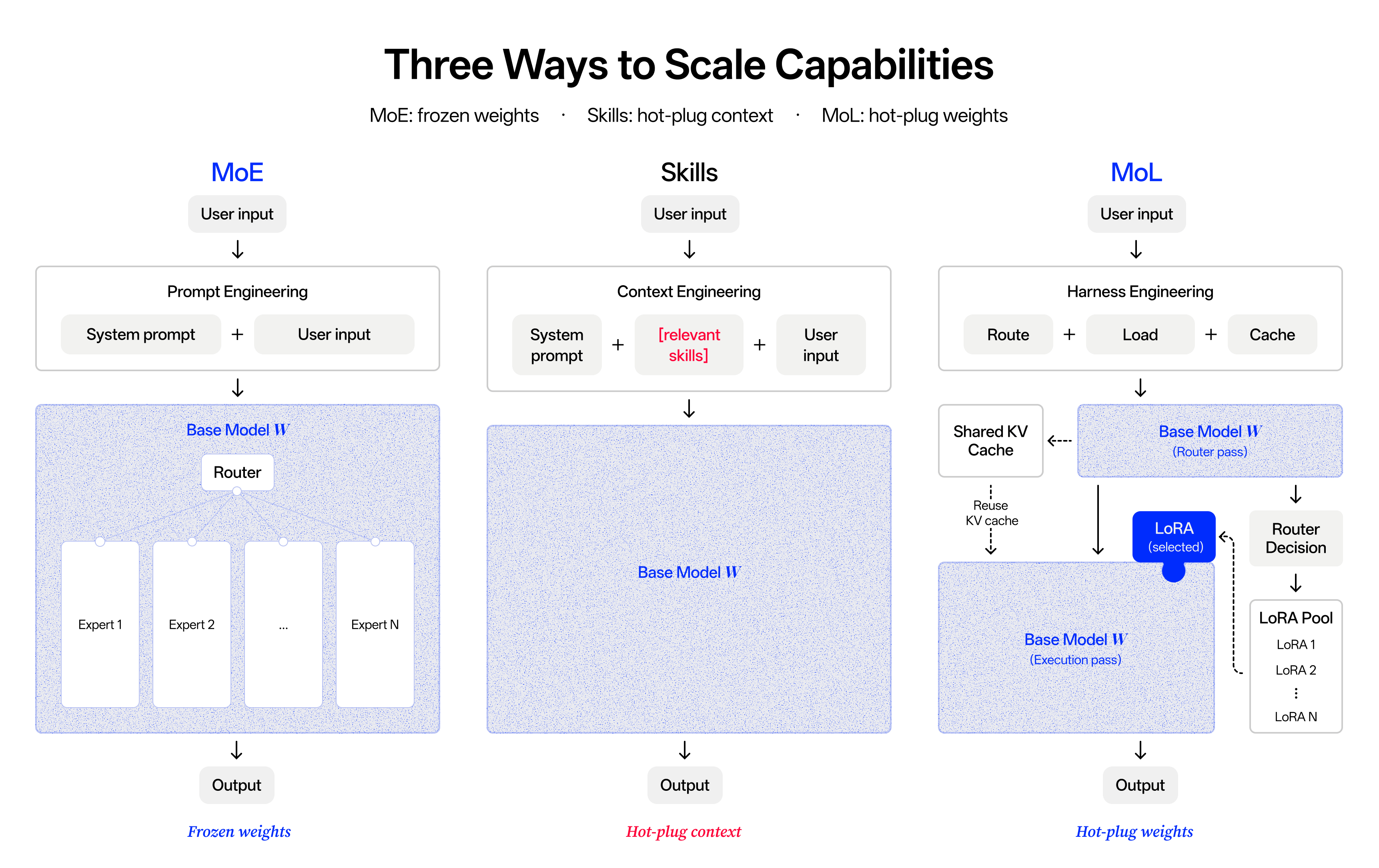
Modern post-training pipelines push a single model through many very different tasks and try to merge the resulting capabilities into one final set of weights. The more we trained Macaron, the clearer it became that chat, tool use, reasoning, and coding rely on different skills and very different chain-of-thought patterns. When those skills share the same parameter space, they start to conflict: improvements in one direction quietly cost capability in another, and the merged model ends up worse than its specialist precursors on the things they each cared about.
Mixture-of-LoRA (MoL) resolves that conflict by design. The idea is simple: cluster tasks that share skills and thinking patterns into one LoRA, and keep tasks whose skills diverge sharply in separate LoRAs over the same frozen base. Similar tasks share a LoRA so they can reinforce each other; tasks with very different skill profiles each get their own. New domains plug in by training and registering one more LoRA, without touching the base or any of the existing specialists. The cost is that something now has to decide which LoRA to use at each turn, and we handle that with a Router Tool, described in §2.2.
Macaron-V1-Preview ships five specialists: L0 for default chat and general-purpose use, L1 for personal-life tasks, L2 for coding tasks, L3 for A2UI, and L4 for OpenClaw-style tasks, with dedicated adaptation to the OpenClaw Harness. Each specialist develops along its own trajectory, and shipping a new capability becomes the act of training and registering one more LoRA.
2.2 Router Tool
Earlier MoE-style work usually trains a dedicated router model. We took a different path. We expose model selection as a tool call, right at the harness level, and let standard infrastructure handle the rest. The default entry adapter is L0, which mounts a single tool, change_model, exposed through standard OpenAI-compatible tool-call APIs. A central LoRA registry is the source of truth, storing model_id, tier, and routing_rule per LoRA, so registering a new specialist is a metadata change. The agentic loop has two phases: explicit routing, where L0 issues a change_model call to switch to the right specialist for the incoming user turn, and implicit routing, where the scaffold returns to L0 once the specialist finishes its turn so the next user message starts again from the default. Routing is debuggable (it shows up as a tool call in traces), serveable on standard infra (vLLM’s OpenAI server mode just works), and reversible (a new L4 is one registry update away).
The Router Tool comes with one real cost: switching LoRAs mid-conversation invalidates the KV cache, since each LoRA modifies the attention computation. Naively, every Router Tool call would mean a full re-prefill on the new specialist. To keep user-facing latency manageable, we ran a series of cross-LoRA KV cache reuse experiments, keeping the existing KV cache through a switch and accepting whatever quality cost that introduces. Reusing the cache costs some accuracy, but the loss stays within an acceptable range for the kinds of switches an agent actually makes. We treat it as a working tradeoff for Macaron-V1-Preview, with room to tighten as MoL serving matures.
2.3 Stabilizing RL on a Sparse Base
RL on a 744B sparse base puts a lot of pressure on training and rollout agreeing about what just happened. We address this in three layers, from the most specific source of mismatch to a general algorithmic safety net.
R3 Router Replay. MoE RL requires the gradient to score each token along the same expert path that generated it at rollout. Small implementation or precision differences can route the same token to different experts during rollout and training, which corrupts the policy gradient. We use R3 (Rollout Routing Replay): MinT records the selected expert ids alongside each rollout token, and at training time the backend replays that route when it can reconstruct the expert path on its current expert-parallel layout; otherwise the token is masked out cleanly. R3 gives provable expert-path alignment on the tokens that contribute to learning.
Sparse attention. DSA introduces a different mismatch channel: the DSA indexer plus the top-k path decides which tokens participate in sparse attention, and small numerical differences can change the attention set itself between rollout and training. We close this at the implementation level, aligning the parts of the DSA stack with concrete causes: indexer RoPE layout, normalized query and key inputs, deterministic top-k behavior, frozen indexer defaults, long-context THD/CP support, and LoRA loading for DSA target modules.
IcePop. R3 covers MoE routing; the implementation fixes cover most structural DSA drift. For everything else, we lean on an IcePop-style rollout correction, consistent with the GLM5 reference implementation: MinT continuously monitors the train-versus-rollout probability ratio per token, and any token whose ratio leaves the trusted band receives zero importance weight, dropping out of the gradient automatically.
2.4 Model and Harness Co-design
§2.3 closes the train-versus-rollout gap at the infrastructure and algorithmic levels. However, the same gap appears in another equally important place: the Agent Harness itself. An agent does not run as a single forward pass. It operates inside a harness that selects LoRAs, manages tool calls, exposes memory, formats system prompts, and tokenizes inputs in a specific way. If we train against a simplified stand-in for that harness, the model learns under conditions it will never encounter at serving time.
We therefore made a deliberate design choice: bring the production Agent Harness directly into training, and treat any divergence between train-time and serving-time harness behavior as a bug to be fixed at the source. MindForge is the agentic RL training framework that brings the production-ready Harness based on Pi Coding Agent into the RL loop, using the same Router Tool, memory layout, tool-call tokenization, and agent harness structure as production serving. The Harness Context Protocol (HCP) is the communication layer that makes this practical: it standardizes how the harness exposes and exports task metadata, memory state, routing instructions, and other configuration information to the model, so the same context schema is used during both training and serving. Anything the model observes during MindForge rollouts is therefore the same thing it can also observe in production serving.
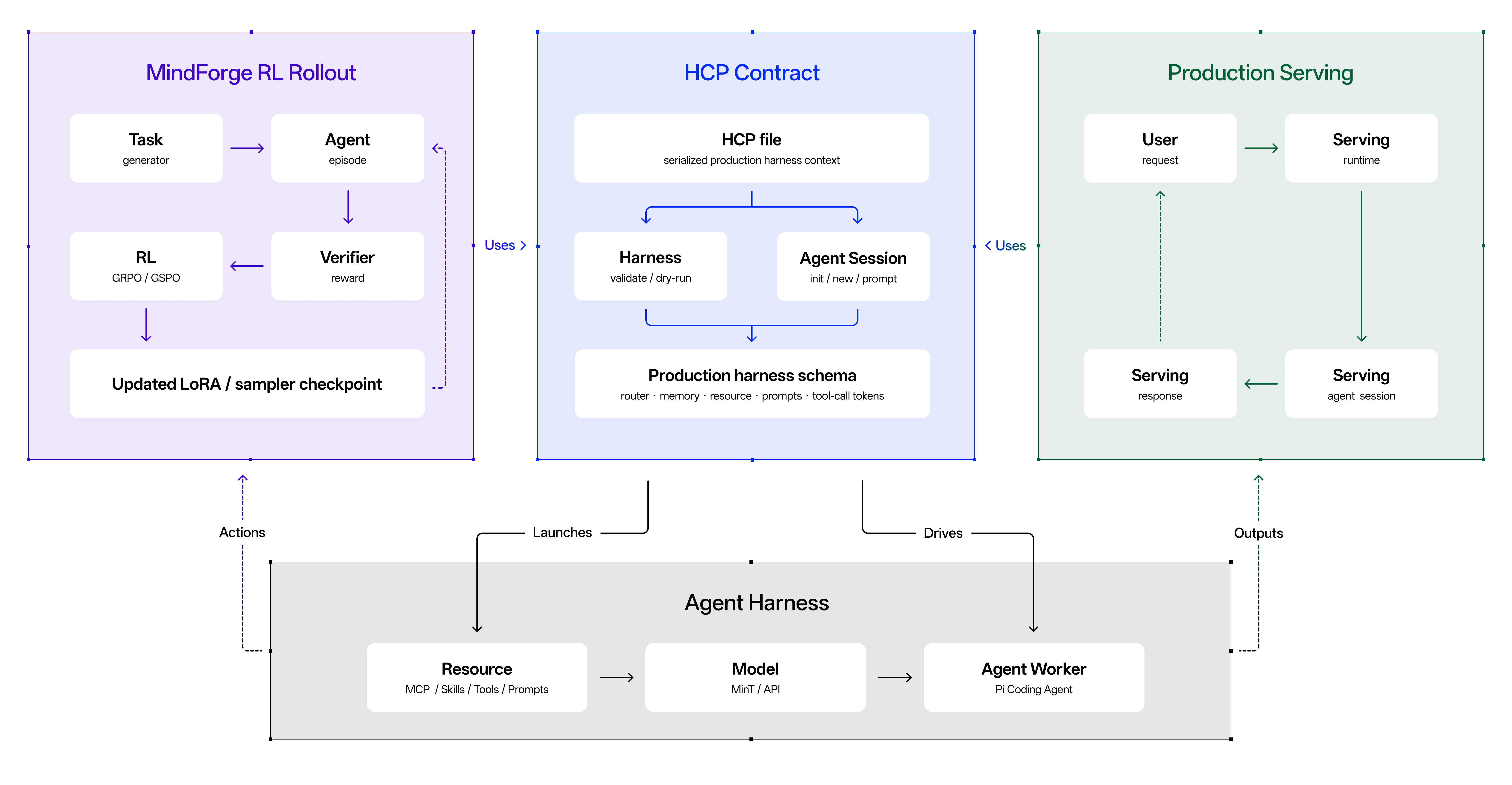
Together, §2.3 and §2.4 chase consistency at three levels: expert routing (R3), sparse-attention provenance plus a probability safety net (DSA fixes + IcePop), and harness behavior (MindForge + Harness Context Protocol). The result is a 744B + DSA + MTP + MoL post-training pipeline that the model can trust, and that ports cleanly to the production environment it serves users from.
2.5 Self-Evolution enabled with AutoResearch and Context Learning
The most interesting result of the project came from a part of the system that we had not originally planned to optimize: the harness itself. Once the harness can be serialized into an HCP configuration, it becomes part of the curriculum rather than just a fixed execution substrate. Then We applied AutoResearch, an established line of work in the broader research community, on HCP configurations to the optimization loop around Macaron. The resulting setup is what we now view as Macaron-V1-Preview’s path toward self-evolution.
The loop has three stages. First, autoresearch: the model improves its own prompts, scaffolds, and tool-use patterns based on natural-language feedback from the environment, all in language space around the frozen weights. Second, trajectory selection: the loop surfaces the trajectories where the rewritten prompts unlock something the original prompts could not. Third, context learning: those better trajectories are distilled back into the model’s parameters, so behavior that was previously available only with a smarter prompt becomes available out of the box, and the next round of context learning starts from a higher baseline.
What we read from this is encouraging and, we think, generalizable: given a well-built environment and a well-shaped reward, current frontier-class models are fully capable of evolving themselves. Self-evolution stops being an aspirational research direction and starts being an operational training signal. This loop is the single biggest lift we observed on VitaBench between Macaron-V1-Preview’s intermediate checkpoints and the released one.
3. How to Access Macaron-V1-Preview
We are shipping Macaron-V1-Preview through four complementary channels.
🤗 Open-source weights on Hugging Face. The Macaron-V1-Preview weights, including the five LoRA specialists and the router metadata, are available for researchers and developers who want to inspect, evaluate, or build on top of the model directly.
🍰 Hosted preview for hands-on use. We host a public Macaron Preview environment so you can talk to the model and feel its personal-agent behavior end-to-end without setting up serving infrastructure. The preview runs on a constrained compute budget, so we apply gentle rate limits to keep the experience smooth, and every conversation that comes back becomes feedback for the next iteration.☕️ Live in the Macaron app. The model is deployed and accessible within the Macaron application, letting you experience its personal-agent capabilities natively in a polished, production-ready environment.
Note: Our newly developed A2UI experience is currently available on the web. The mobile app is still using the earlier version of A2UI for now, but we are actively working on the rollout and plan to bring the new experience to mobile as soon as possible.
🌿 Managed inference and post-training on MinT (coming soon). The inference and post-training capabilities will be made available on MinT, our own managed post-training infrastructure, providing you with the tools you need to efficiently adapt and serve the model for your own use cases.
The post tells you what we built and why; the preview lets you feel it firsthand.
4. What This Preview Is, and What Comes Next
Macaron-V1-Preview is exactly that, a preview. We are shipping it now because the architecture is settled enough that external feedback is the most valuable thing we can collect, and the LivingBench loop only gets richer when more real users push on it.
Between now and the V1 (non-preview) release, three things change:
- Flagship 744B + 5 × 1B keeps iterating against feedback collected during the preview window.
- Two open-source variants land: a 30B and a 200B Macaron-V1, sharing the MoL recipe over smaller bases.
- Full benchmark suite ships with reproducible scripts and seeds.
Thanks to everyone in the Macaron App community whose conversations, feedback, and corrections shaped this model. Quite literally.
Appendix
Contribution
Mind Lab
Team
Vin Bo, Song Cao, Vic Cao, Andrew Chen, Kaijie Chen, Cleon Cheng, Steven Chiang, Kaixuan Fan, Hera Feng, Huan Feng, Arthur Fu, Jun Gao, Hongquan Gu, Aaron Guan, Nolan Ho, Mutian Hong, Hailee Hou, Peixuan Hua, Charles Huang, Miles Jiang, Nora Jiang, Yuyi Jiang, Qiuyu Jin, Fancy Kong, Andrew Lei, Kyrie Lei, Alexy Li, Lucian Li, Ray Li, Theo Li, Wenhao Li, Zhihui Li, Allen Lin, Jiayi Lin, Kairus Liu, Kieran Liu, Logan Liu, Xiang Liu, Irvine Lu, Maeve Luo, Runze Lv, Pony Ma, Verity Niu, Anson Qiu, Vincent Wang, Rio Yang, Maxwell Yao, Carrie Ye, Regis Ye, Wenlin Ye, Josh Ying, Danney Zeng, Yuhan Zhan, Anya Zhang, Di Zhang, Ruijia Zhang, Shiyang Zhang, Sueky Zhang, Ya Zhang, Wei Zhao, Ada Zhou, Adrian Zhou, Yuhua Zhou, Xinyue Zhu, Murphy Zhuang.
Names are listed alphabetically.
Citation
Please cite this work using the BibTeX citation:
@misc{mindlab2026macaronv1preview,
author = {{Mind Lab}},
title = {Macaron-V1-Preview: 749B MoL Agent Model post-trained from GLM5.1},
year = {2026},
howpublished = {Mind Lab: A Lab for Experiential Intelligence},
note = {https://macaron.im/mindlab/research/macaron-v1-preview}
}